Ответ:
Модель или данные остаются у владельца.
К ним едет вычисление, а не данные к модели.
HFL · Федеративный файнтюнинг
Проблема
Модель развёрнута в контуре клиента. Пошёл дрейф, точность падает, а держать её по SLA надо.
Дообучить нужно на данных клиента, но вытащить их из контура нельзя.
Решение
Дообучаем модель прямо в контуре клиента. К данным едет модель.
Точность держится, данные не уходят, права на модель остаются у вендора.
Вы Владелец модели
Идеально для



Вертикальное обучение
Проблема
Банки хотят обогащать свои модели вашими данными - скоринг, антифрод, риски.
Спрос есть, но захватить его нечем: продать исходные данные нельзя, а проданный датасет перестаёт быть вашим активом.
Решение
Данные становятся подключаемым сервисом вместо датасета на продажу. Клиент подключается к вашей ноде и обучает общую модель.
Никто не видит исходные данные другого. Данные остаются у вас, доход с каждого инференса.
Вы Владелец данных
Идеально для



Без знаний Python, криптографии и федеративного обучения


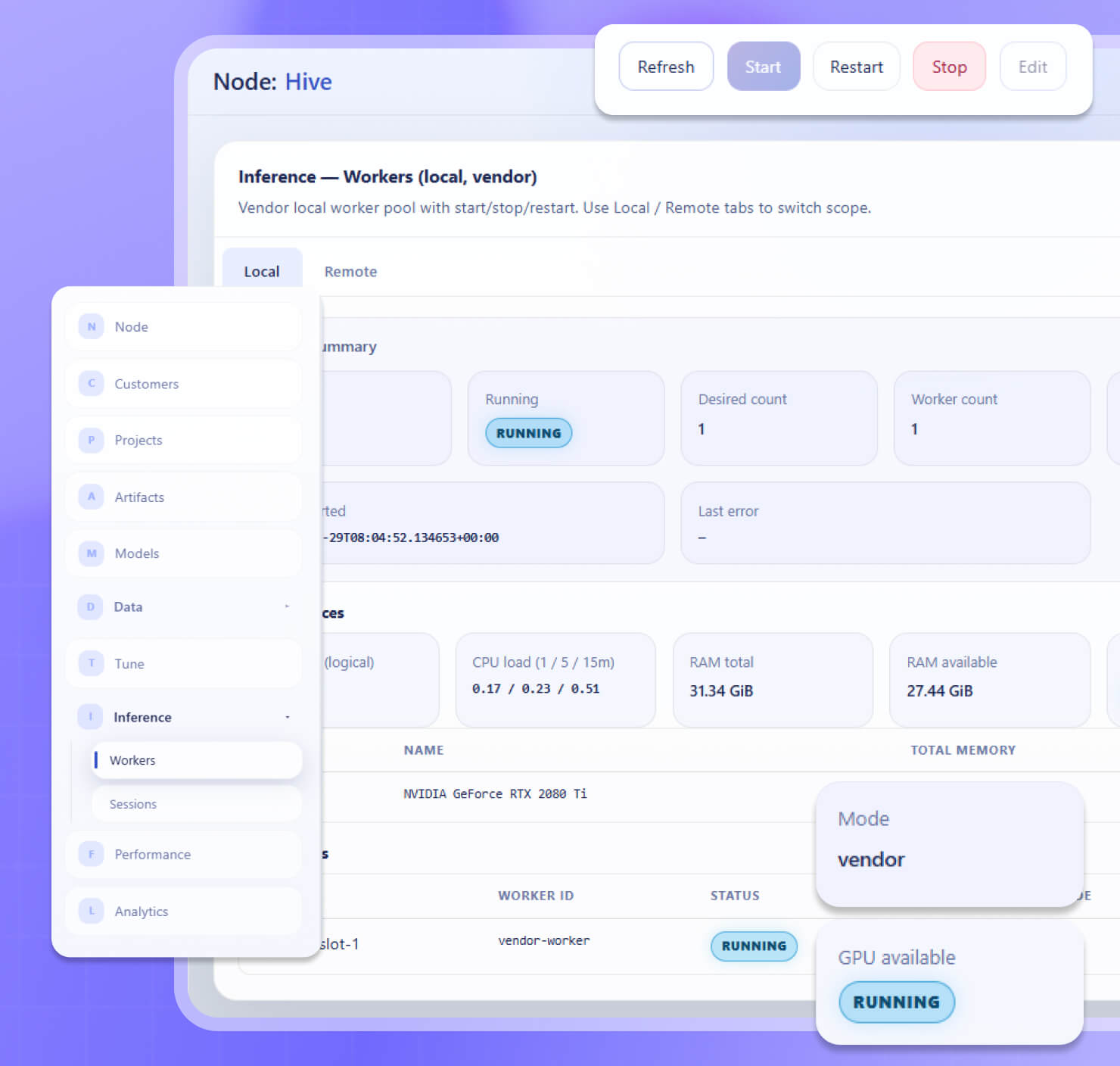
Вендор управляет обучением, клиент только запускает модель в своём контуре.

Сторона вендора
Полный контроль: обучение, Start/Stop, GPU

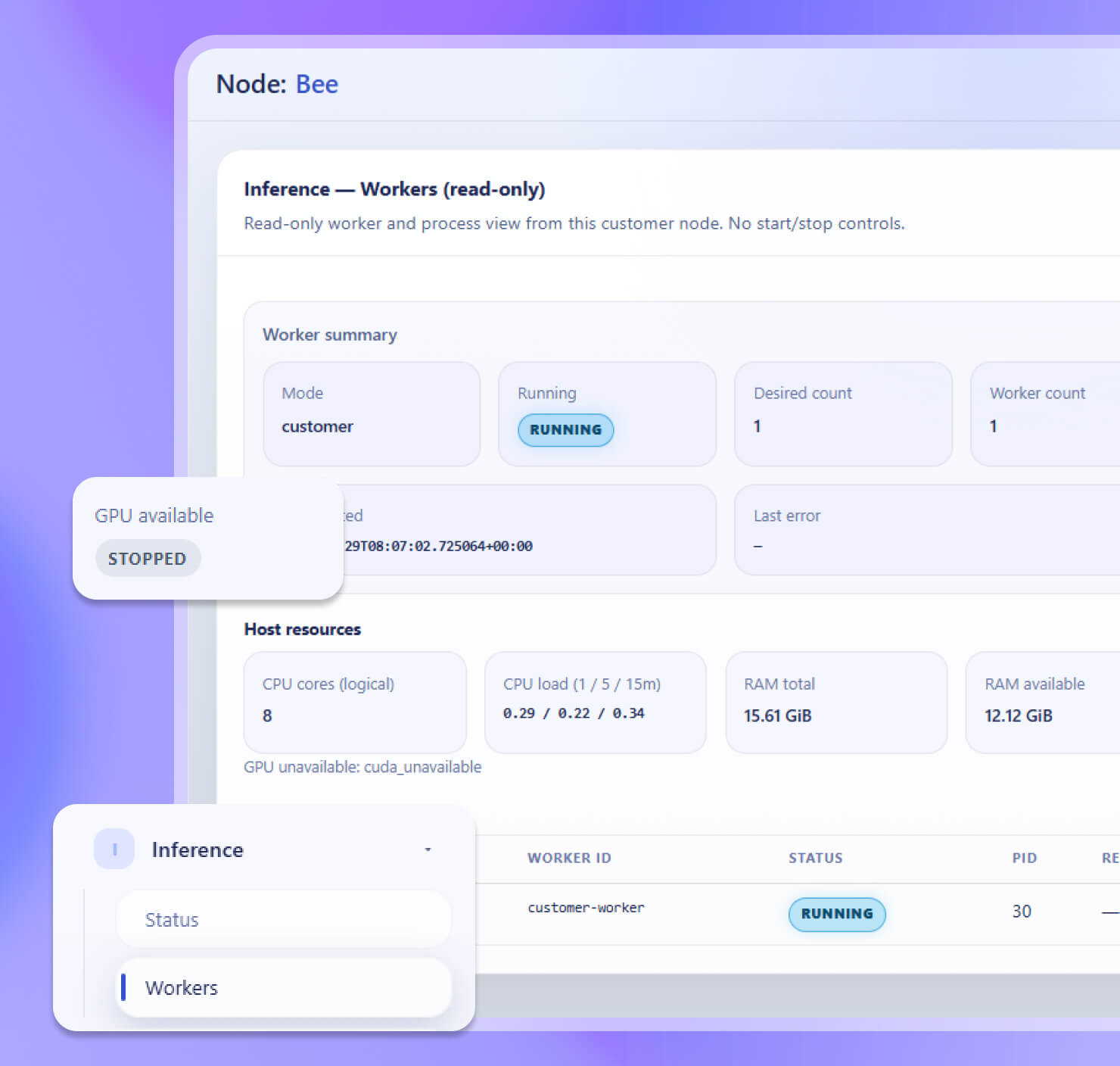
Сторона клиента
Read-only, без управления
Участники подключают узлы и обучают общую модель, не раскрывая исходные данные.
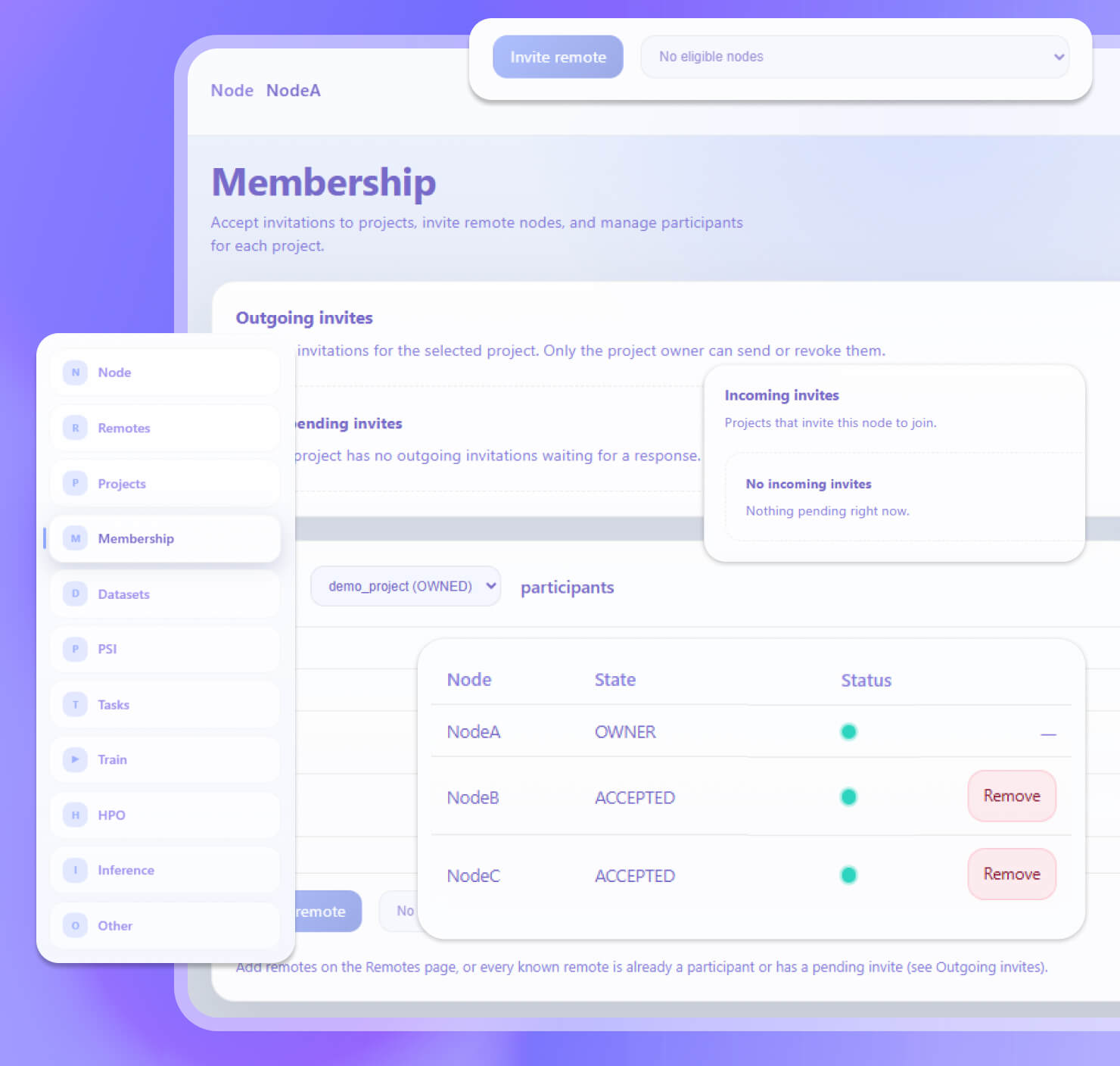
Рабочее пространство
Приглашение узлов и управление участниками проекта.
Безопасная передача параметров ML-модели
Без хранения данных
Наш продукт выполняет все — вам не нужно быть гуру Python, экспертом по федеративному обучению, криптографом, дата-сайентистом или системным администратором
Получение ответа сети в защищенном виде
Безопасный инференс
Применяя решения Guardora в ваших продуктах, вы обеспечиваете их соответствие законодательству по защите данных и внутренним стандартам безопасности.
Преимущество
Улучшите качество
ML-моделей без передачи
сырых данных
Преимущество
Безопасно монетизируйте знания, а не датасеты
Преимущество
Обойдите конкурентов,
предлагая ML-продукты,
гарантирующие защиту данных
Преимущество
Соответствуйте требованиям
по безопасности данных
Федеративное обучение
Обучение общей ML модели на датасетах нескольких компаний так, что данные не покидают доверенного контура каждой из компаний-участников федеративного обучения.
Это как коллективный мозговой штурм, где все вносят идеи, не раскрывая свои мысли.
Гомоморфное шифрование
Приватные вычисления над параметрами модели — без расшифровки
Представьте, что вы решаете головоломку, не вынимая её из коробки.
С помощью гомоморфного шифрования параметры модели остаются зашифрованными даже во время обучения и вывода.
Сырые данные не затрагиваются — и при этом всё работает. Это означает сверхбезопасное сотрудничество без ущерба для качества модели.
Дифференциальная приватность
Шум — там, где это действительно важно
Добавление откалиброванного шума к параметрам модели предотвращает утечку индивидуальной информации.
Результат — надёжная приватность с моделями, которые остаются точными и эффективными.