Федеративное машинное обучение для оценки кредитных рисков в BFSI
Отрасли
Банковское дело, финансовые услуги, страхование
Техника
Вертикальное федеративное обучение (VFL)
Тип данных
Табличные (структурированные) данные
ML-модель
Деревья решений (XGBoost)
ML-задачи
Оценка кредитных рисков и мошенничества
Задачи

Портрет пользователей федеративного обучения охватывает представителей банковского сектора и страхования, которые используют модели для предсказания рисков, оценки заемщиков и борьбы с мошенничеством.
Высокая потребность в соблюдении законодательства по защите данных.
Необходимость интеграции разнообразных источников данных.
Использование данных для предсказательной аналитики и кредитных оценок.
Основной вызов — обучение скоринговых моделей, используя конфиденциальные данные из разных источников, таких как банки и страховые компании, без раскрытия самих данных. Задачи включают защиту данных от утечек, обеспечение анонимности и соблюдение законов о конфиденциальности.
Федеративное машинное обучение используется для построения моделей кредитного скоринга и оценки рисков, не раскрывая личные данные.
Проблемы включают:

Данные не покидают контур владельца.
ML-специалист и ресурсы находятся внутри контура владельца данных.
Защищённая синхронизация параметров локальной и глобальной модели с сервером
Проверка качества итоговой модели
Применение модели внутри контура владельца данных и интерпретация полученных результатов
Для обеспечения возможности извлечения знаний из данных обоих участников потребовалось развернуть инфраструктуру вертикального федеративного обучения.
Характер исходных данных предопределил выбор целевой модели в виде градиентного бустинга на основе решающих деревьев в реализации XGBoost.
Сторона, располагающая целевыми метками классов, названа серверной стороной; не имеющая таргетов ― клиентской стороной.
Для публичной демонстрации результатов был использован датасет, включающий:
Банковские данные находятся на серверной стороне ― всего 78 806 записей, содержащих описания персон на основе 12 признаков. Данные автострахования ― на клиентской, 97 224 записей по 9 признаков для каждой персоны. Каждый из датасетов содержит поле ID, позволяющее произвести сопоставление данных, относящихся к одной персоне. Каждая персона из пересечения датасетов описывается 21 признаком, которые находятся у двух сторон. Часть данных из пересечения была выделена в тестовый сет из 25 668 записей, остальная ― в обучающий.
Проводилось два цикла обучения модели XGBoost:
Для обоих случаев зафиксированы идентичные параметры модели:
| 'objective': 'multi:softmax' | 'num_class': 3 |
| 'eval_metric': 'merror' | 'max_depth': 6 |
| learning_rate': 0.1 | 'subsample': 0.8 |
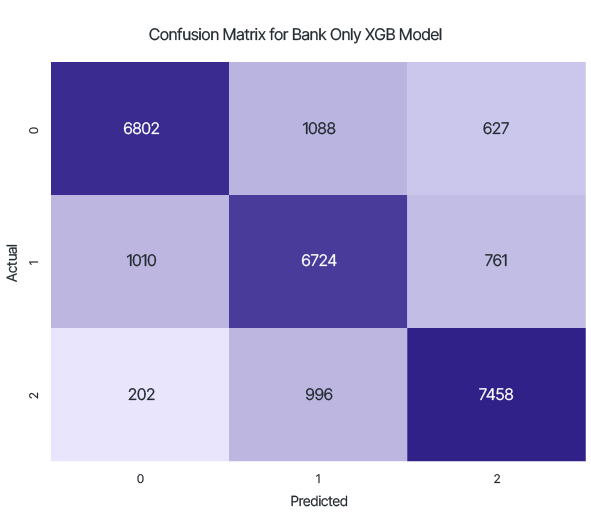
Итог тестирования локальной модели,
обученной только на данных серверной стороны:
Точность: 0.817
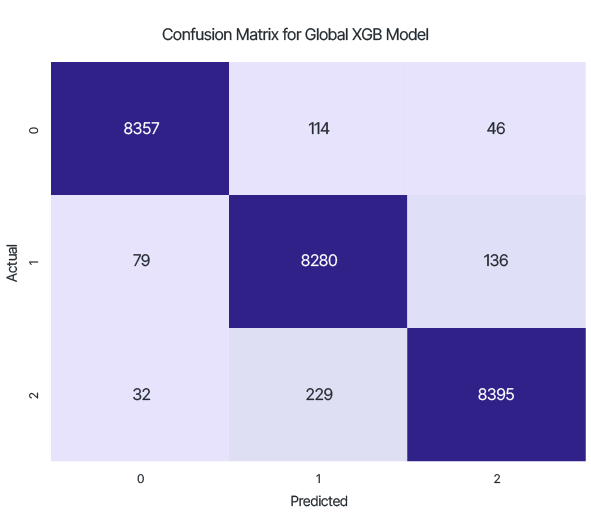
Итог тестирования глобальной модели,
обученной на данных серверной и клиентской сторон:
Точность: 0.975
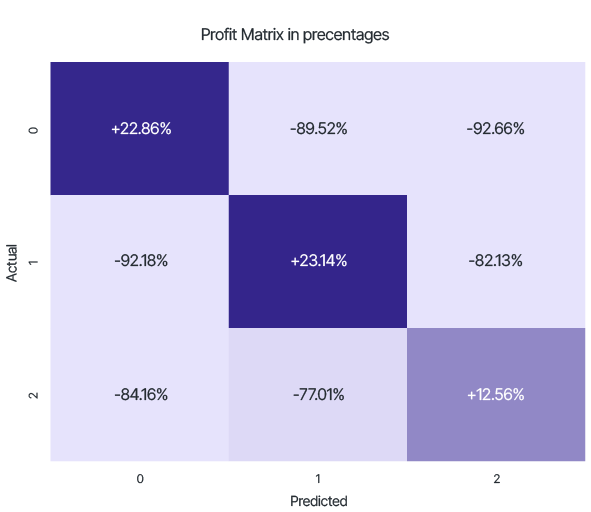
Профит от использования такого подхода по сравнению с возможностью локальной модели:
Из данной матрицы можно видеть, что, например, количество тестовых образцов с низким кредитным скором, но отнесенных обученной моделью к высокому рейтингу, сократилось на 92,66% при использовании глобальной модели федеративного обучения.
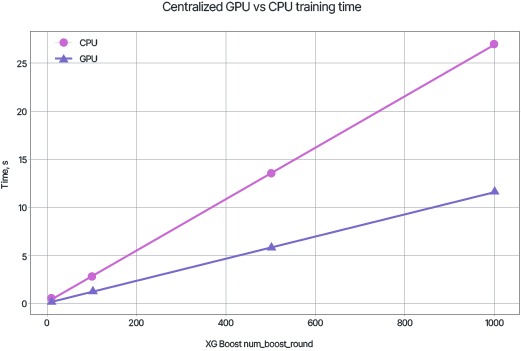
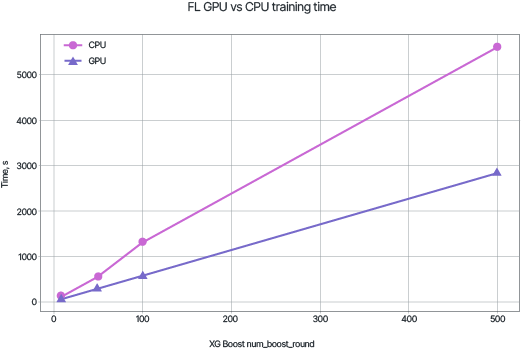
Стоит отметить, что процесс распределенного обучения более длителен, нежели централизованного. Графики демонстрируют зависимость необходимого времени для обучения модели с задаваемым количеством деревьев с использованием CPU и GPU.
Несмотря на существенные временные затраты, высокая скорость сходимости модели позволяет VFL оставаться практически ценным методом для обобщения информации из накопленных данных.
Повышение точности кредитных скоринговых моделей более чем на 15%.
Снижение риска невозврата кредитов и мошенничества.
Увеличение уровня предсказания оттока клиентов и улучшение клиентского опыта.
Скоринговая модель была обучена на данных из разных источников (банк и страховая) при полном соблюдении конфиденциальности.
