

Обучение моделей только на новых поступающих данных приводит к значительному ухудшению производительности (возникает «проблема забывания», когда модель забывает предыдущие примеры после обучения на новых данных); в то же время хранение всех исторических данных крайне затруднительно, если вообще реализуемо.
Большинство методов сокращения данных сводится к выбору наиболее репрезентативных/ценных образцов из оригинальных наборов данных (датасетов). Вот только при существенном уменьшении количества отобранных данных обучение на них становится малоэффективным.
В отличие от этих методов дистилляция датасета (Dataset Distillation), также называемая конденсацией датасета (Dataset Condensation), это не выбор из имеющихся, а синтез небольшого количества новых объектов S (синтетических данных), которые агрегируют полезную информацию, хранящуюся в оригинальных данных T, и позволяют обучать алгоритмы машинного обучения практически так же эффективно, как и на всех данных (рис. 1).
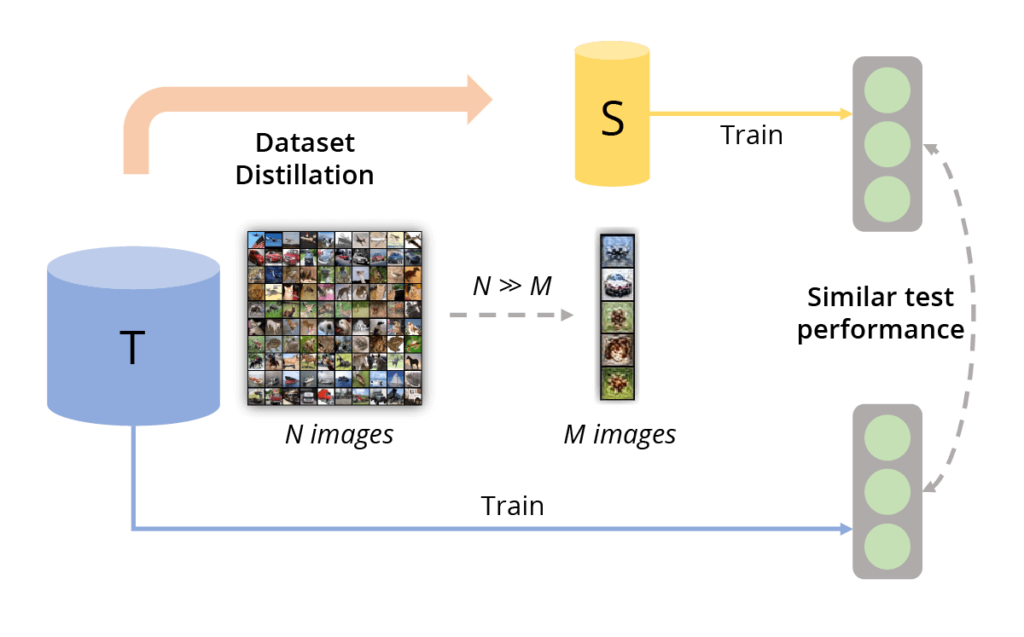
Рис. 1 (источник: [1]) Принцип работы дистилляции данных. Дистилляция датасетов направлена на создание небольшого информативного набора данных, чтобы модели, обученные на этих образцах, имели схожую тестовую производительность с моделями, обученными на исходном наборе данных.
Впервые этот подход был предложен в 2018 году в работе [2]. Авторы успешно сократили датасет MNIST из 60 000 изображений рукописных цифр всего до 10 элементов (по одному изображению-представителю для каждого класса)! При этом модель достигла точности обучения 94% с использованием синтетических данных, что сопоставимо с точностью 99% на полном наборе данных. На рис. 2 показан основной результат из работы [2] и полученные синтетические данные в задачах MNIST и CIFAR10.

Рис. 2 (источник: [2]) Знания десятков тысяч изображений сводятся к нескольким синтетическим обучающим изображениям, называемым дистиллированными. На MNIST 10 дистиллированных изображений позволяют обучить стандартную сеть LENET с фиксированной инициализацией с точностью 94%, по сравнению с 99% при полном обучении. На CIFAR10 100 дистиллированных изображений позволяют обучить сеть с фиксированной инициализацией с точностью 54% при тестировании, по сравнению с 80% при полном обучении.
Классификация методов дистилляции
Идея дистилляции данных сразу же привлекла к себе внимание исследователей, появились новые методы дистилляции (рис. 3), в том числе дистилляция изображений вместе с их метками ([3]). Дистилляцию стали применять не только к изображениям, но и к текстам ([3], [4]), графам ([5], [6]) и даже рекомендательным системам ([7]).
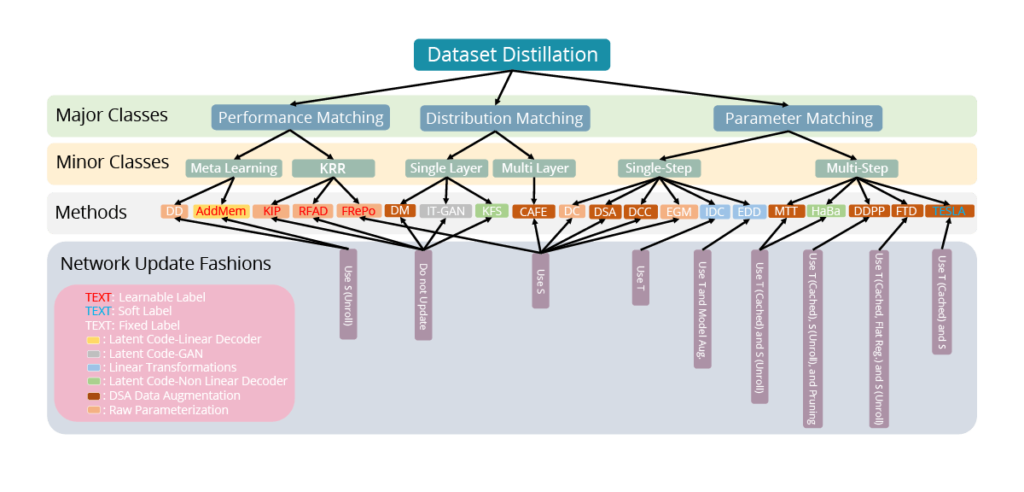
Рис. 3 (источник: [1]) Таксономия существующих методов дистилляции данных. Метод дистилляции данных может быть проанализирован с четырёх сторон: цель оптимизации, способ обновления сетей, параметризация синтетических данных и способ обучения меток.
Тем не менее основных подходов, обеспечивающих эффективность дистиллированных данных, можно выделить три: сопоставление производительности (Performance Matching), сопоставление параметров (Parameter Matching) и сопоставление распределений (Distribution Matching).
Performance matching
Сопоставление производительности предполагает оптимизацию синтетического набора данных таким образом, чтобы минимизировать потери обученных на нём нейронных сетей при работе с исходным набором данных. Целью является достижение сопоставимых показателей и результатов в обоих случаях (как на синтетических, так и на оригинальных данных).
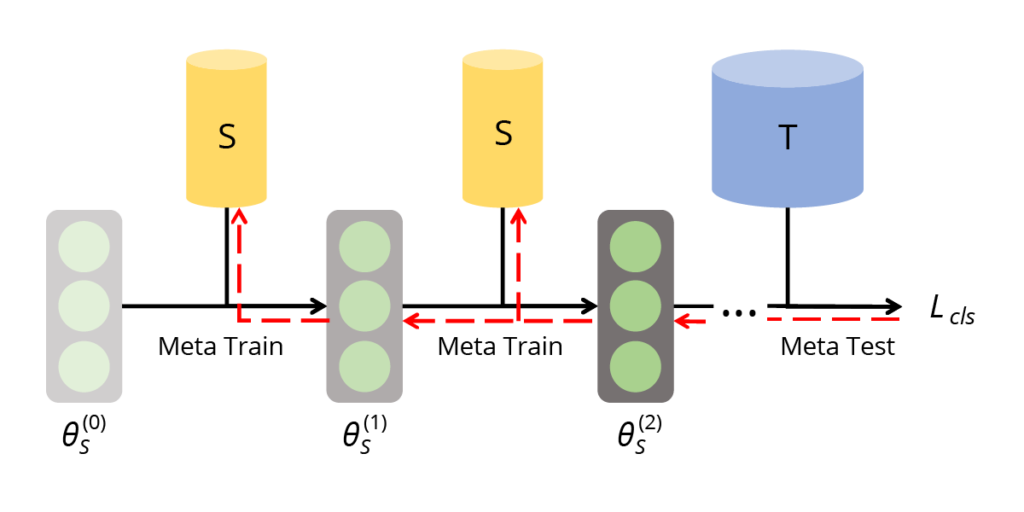
Рис. 4 (источник: [1]) Согласование производительности на основе метаобучения. Двухуровневая система обучения направлена на оптимизацию потерь при метатестировании на реальном наборе данных T для модели, метаобученной на синтетическом наборе данных S.
Parameter matching
С другой стороны, сопоставление параметров направлено на одновременное обучение нейронной сети как на синтетическом наборе данных, так и на исходном. Этот подход направлен на обеспечение единообразия параметров модели в обоих случаях. Существует два варианта этого подхода: одношаговый (сопоставление градиентов) и многошаговый (сопоставление траекторий обучения).
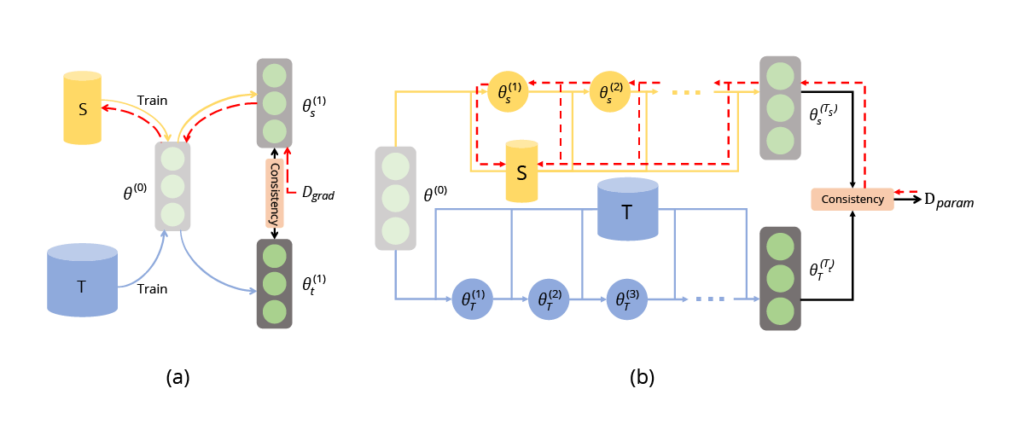
Рис. 5 (источник: [1]) (a) Одношаговое согласование параметров. (b) Многоступенчатое согласование параметров. Они оптимизируют согласованность параметров обученной модели на основе реальных и синтетических данных. Для одноэтапного согласования параметров это эквивалентно согласованию градиентов. Для многоэтапного согласования параметров это также известно как согласование траекторий обучения.
Distribution matching
В отличие от двух предыдущих подходов, направленных на оптимизацию модели, сопоставление распределений напрямую оптимизирует расстояние между распределениями данных. Цель состоит в том, чтобы получить синтетические данные, которые будут максимально приближены к распределению реальных данных.
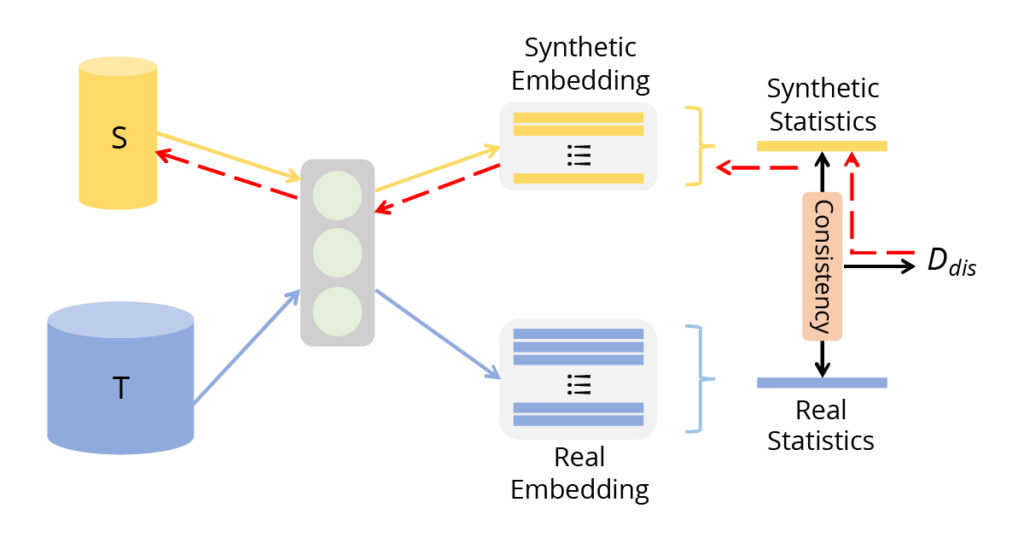
Рис. 6 (источник: [1]) Согласование распределений. Оно сопоставляет статистику признаков в некоторых сетях для синтетических и реальных наборов данных.
Дистилляция данных как метод защиты приватности оригинальных данных
Важно отметить, что ни один из описанных выше подходов не требует визуального сходства между дистиллированными и оригинальными изображениями. Результаты применения многих методов дистилляции больше похожи на шум, чем на оригинальные изображения (рис. 2). Благодаря этому свойству дистилляция данных стала использоваться не только для сжатия датасетов, но и для визуальной анонимизации данных.
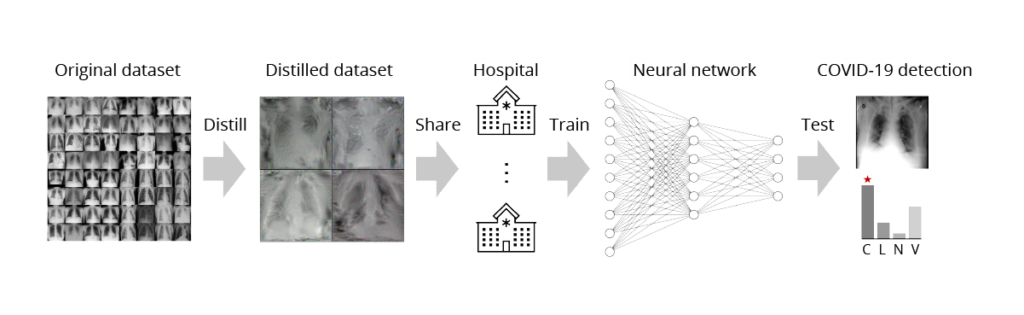
Можно найти работы, которые используют дистилляцию для безопасной передачи медицинских изображений ([8], [9]). Как известно, обмен медицинскими данными представляет собой сложную задачу, связанную с защитой конфиденциальности данных и огромными затратами на передачу и хранение большого количества медицинских изображений высокого разрешения. Однако эту задачу можно решить, передавая дистиллированные данные вместо исходных (рис. 7).
Дистилляция также может использоваться в федеративном обучении ([10]). Традиционный подход предполагает, что клиенты проводят обучение локально и во время каждой итерации передают на сервер большие веса модели вместо обмена конфиденциальными данными. Однако альтернативный подход предполагает, что клиенты могут дистиллировать свои данные и отправить синтезированные данные на сервер, где на них будет обучаться глобальная модель. Такой подход эффективно минимизирует частоту дорогостоящих коммуникаций и обеспечивает конфиденциальность исходных данных.
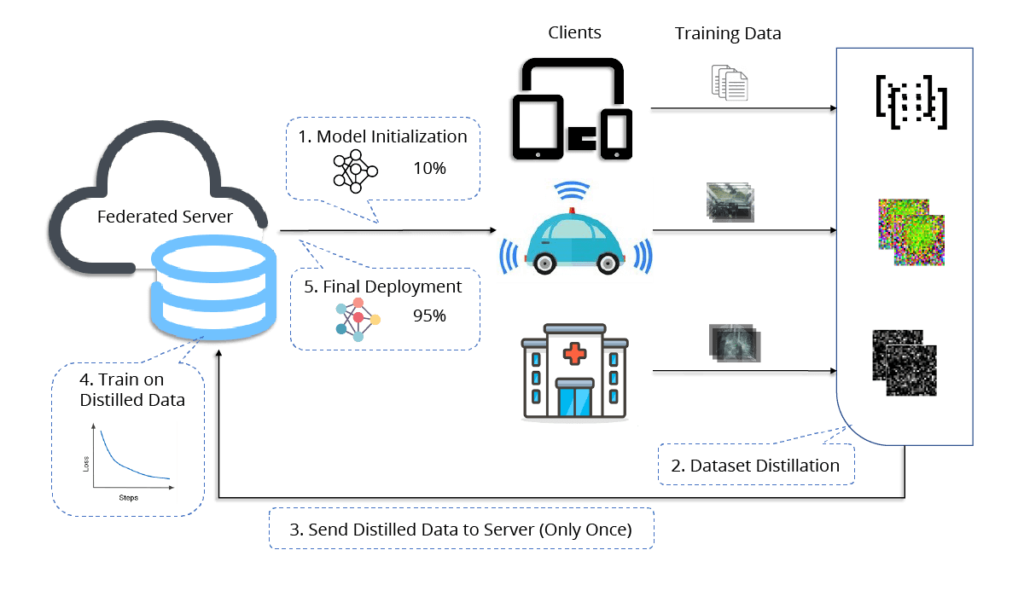
Рис. 8 (источник: [10]) Дистиллированное одномоментное федеративное обучение. (1) Сервер инициализирует модель, которая передается всем клиентам. (2) Каждый клиент распределяет свой частный набор данных и (3) передает синтетические данные, метки и скорость обучения на сервер. (4) Сервер подгоняет свою модель к полученным данным и (5) распространяет окончательную модель среди всех клиентов.
Но действительно ли безопасно использовать дистиллированные данные вместо оригинальных? В работе [11] авторы приводят эмпирическое подтверждение эффективности защиты данных посредством дистилляции. Они проводят серию атак на модели, обученные на дистиллированных данных, чтобы определить вероятность принадлежности некоторого образца исходному набору данных (так называемые Membership Inference Attacks). Их результаты показывают, что вероятность успеха таких атак составляет примерно 50%, что сравнимо со случайным угадыванием и указывает на хорошую защиту.
Но эти выводы оспаривают авторы работы [12]. Они утверждают, что теоретический анализ и эмпирические оценки коллег не предоставляют статистически достоверных подтверждений тому, что дистилляция данных действительно обеспечивает надежную защиту оригинальных данных.
Дифференциальная приватность
Тем не менее идея использования дистилляции данных для сохранения приватности оригинальных данных заинтересовала многих исследователей, и в этом направлении удалось получить результаты со строгим доказательством. Так, в работе [13] впервые применяется DP-SGD во время дистилляции. DP-SGD (Differentially Private Stochastic Gradient Descent) — это широко используемый алгоритм дифференциальной приватности, который включает в себя введение калиброванного гауссова шума в градиенты во время обучения. Фундаментальный принцип дифференциальной приватности заключается в защите приватности каждого отдельного элемента набора данных, обеспечивая в том числе устойчивость к потенциальным атакам, таким как в [11].
Предложить более эффективный метод дифференциально приватной дистилляции пытаются авторы работы [14], но они сталкиваются с другой проблемой — высокой вычислительной сложностью (требуется параллельное использование сотен GPU V100 — ресурсы, которые мало кому доступны). Решая эту проблему, они предлагают альтернативные варианты, для которых достаточно всего одного GPU V100. Если же оценивать эффективность синтезированных их методом данных, то для датасета MNIST и 10 дистиллированных изображений (по 1 на каждый класс) получается точность 94.7% (практически на уровне 2018 года, но зато с гарантиями приватности), в то время как тот же самый метод без DP-SGD (а значит без гарантий приватности) достигает 98.2%.
Таким образом, несмотря на наличие дифференциально приватных методов дистилляции, пока рано говорить об их широком применении на практике, так как они делают и без того довольно сложный процесс дистилляции ещё более тяжёлым и ресурсоемким, а полученные синтетические данные менее эффективными.
Также не стоит забывать и о других минусах дистилляции, таких как отсутствие гибкости и универсальности синтетических данных: во-первых, дистиллированные данные заточены под конкретную классификационную задачу (с конкретными метками), во-вторых, под определённую модель, поэтому вряд ли получится обучить на дистиллированных данных нейросеть произвольной архитектуры до желаемого качества. Дистиллированные данные не являются полноценной заменой оригинальных данных.
Все это делает дистилляцию данных безусловно интересной, но достаточно тяжёлой для практического использования в целях обеспечения приватности реальных данных. Однако методы дистилляции быстро развиваются и совершенствуются!
Источники
[1] Ruonan Yu, Songhua Liu and Xinchao Wang. Dataset distillation: A comprehensive review. arXiv preprint arXiv:2301.07014, 2023
[2] Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959, 2018
[3] Ilia Sucholutsky and Matthias Schonlau. Soft-label dataset distillation and text dataset distillation. In 2021 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE, 2021
[4] Yongqi Li and Wenjie Li. Data distillation for text classification, arXiv preprint arXiv:2104.08448, 2021
[5] Wei Jin, Lingxiao Zhao, Shichang Zhang, Yozen Liu, Jiliang Tang and Neil Shah. Graph condensation for graph neural networks, arXiv preprint arXiv:2110.07580, 2021
[6] Jin, Wei and Tang, Xianfeng and Jiang, Haoming and Li, Zheng and Zhang, Danqing and Tang, Jiliang and Yin, Bing. Condensing graphs via one-step gradient matching, in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 720–730
[7] Noveen Sachdeva, Mehak Preet Dhaliwal, Carole-Jean Wu and Julian McAuley. Infinite recommendation networks: A data-centric approach, arXiv preprint arXiv:2206.02626, 2022
[8] Li, Guang and Togo, Ren and Ogawa, Takahiro and Haseyama, Miki. Dataset distillation for medical dataset sharing, arXiv preprint arXiv:2209.14603, 2022
[9] Li, Guang and Togo, Ren and Ogawa, Takahiro and Haseyama, Miki. Compressed gastric image generation based on soft-label dataset distillation for medical data sharing, Computer Methods and Programs in Biomedicine, vol. 227, p. 107189, 2022
[10] Yanlin Zhou, George Pu, Xiyao Ma, Xiaolin Li and Dapeng Wu. Distilled one-shot federated learning, arXiv preprint arXiv:2009.07999, 2020
[11] Tian Dong, Bo Zhao and Lingjuan Lyu. Privacy for free: How does dataset condensation help privacy? arXiv preprint arXiv:2206.00240, 2022
[12] Nicholas Carlini, Vitaly Feldman and Milad Nasr. No Free Lunch in "Privacy for Free: How does Dataset Condensation Help Privacy", arXiv preprint arXiv:2209.14987, 2022
[13] Dingfan Chen, Raouf Kerkouche and Mario Fritz. Private set generation with discriminative information, arXiv preprint arXiv:2211.04446, 2022
[14] Margarita Vinaroz and Mi Jung Park. Differentially Private Kernel Inducing Points using features from ScatterNets (DP-KIP-ScatterNet) for Privacy Preserving Data Distillation, arXiv preprint arXiv:2301.13389, 2024


