Федеративное машинное обучение для обнаружения мошенничества в банковских транзакциях
Отрасль
Банки, платежные системы, FinTech, предотвращение и обнаружение мошенничеств
Техника
Горизонтальное федеративное обучение (HFL)
Типы данных
Табличные
ML-модели
Random Forest (RF) и Gradient-Boosted Decision Trees (GBDT)
ML-задачи
Обнаружение мошенничеств в транзакциях с банковскими картами
Задачи PPML

Банк заинтересован в предотвращении мошенничества с банковскими картами для защиты средств клиентов, минимизации собственных финансовых потерь и повышения доверия клиентов к банку.
Платежная система стремится обеспечить безопасность операций, снизить репутационные риски, связанные с мошенническими транзакциями, и поддерживать доверие пользователей к своим услугам и банковской системе в целом.
Защита конфиденциальности данных клиентов - критически важная задача как для банка, так и для платежной системы, особенно в условиях ужесточения регулирования обработки персональных данных.
Стремление к снижению финансовых потерь и минимизации рисков через внедрение эффективных технологий предотвращения мошенничества.
Укрепление доверия клиентов за счет повышения безопасности и надежности финансовых операций.
Бизнес-задача: выявление мошеннических действий с использованием банковских карт в процессе транзакций.
Основная цель — повысить точность обнаружения мошенничества в режиме реального времени, обеспечивая при этом защиту персональных данных.
Техническая задача: разработка и внедрение федеративно обученной ML-модели для обнаружения мошеннических транзакций на основе совместных данных банка и платежной системы.
Модель должна:
В качестве моделей машинного обучения рассматриваются Random Forest и Gradient-Boosted Decision Trees (GBDT), которые обеспечивают высокую точность и надежность в задачах выявления мошенничества.

Данные не покидают контур владельца. ML- специалист и ресурсы находятся внутри контура владельца данных
Защищённая синхронизация параметров локальной и глобальной модели с сервером
Проверка качества итоговой модели
Применение модели внутри контура владельца данных и интерпретация полученных результатов
В рамках взаимодействия банков и платежных систем Guardora продемонстрировала практическую ценность технологии федеративного машинного обучения (FL) по выявлению мошенничеств в банковских транзакциях.
Участники FL имеют различные пайплайны генерации признаковых пространств. Для признаков, образующих пересечение этих пространств, были согласованы схемы получения и предобработки.
С целью обеспечения открытого равнодоступного аудита процесс FL был развернут в приватном облаке с участием двух клиентских серверов и одного агрегирующего.
Специфичность задачи детектирования мошеннических транзакций состоит в колоссальном дисбалансе классов. Порядка 0.01-0.001 транзакций представляют из себя мошенничества в реальном потоке данных. Это препятствуют широкому внедрению ML-алгоритмов для решения такой задачи.
В первую очередь мошенничеству подвержены небольшие финансовые организации, не располагающие достаточно репрезентативным набором данных.
Зачастую классификация транзакций осуществляется путем построения сложных наборов правил (“rule based”).
Участники сообщили, что датасеты включали такие группы характеристик транзакций, как данные плательщика, временные и финансовые данные, информация о платеже, географическая информация, информация о сети, информация о девайсе, профилированное поведение и др.
Описание датасетов:
| data_A | data_B | |
|---|---|---|
| Количество признаков | 93 | 93 |
| Количество легальных | 69341 | 29141 |
| Количество мошенничеств | 843 | 859 |
| Доля мошенничеств | 0.012 | 0.029 |
Видна характерная диспропорция классов. Участники приняли решение использовать модели на основе решающих деревьев; таким образом, сравнивалась эффективность Random Forest (RF) и Gradient-Boosted Decision Trees (GBDT) моделей.
Набор данных, на которых тестировалась обученная модель, был сформирован и зафиксирован случайным выбором 20% из каждого сета.
Ввиду значительного дисбаланса была использована метрика PR-AUC, вычисляющая площадь под кривой, которая отражает соотношение Precision и Recall при различных порогах классификации. Для наглядности отражения классификационной способности обученной модели при пороге 0.5 использован Confusion matrix.
Результаты тестирования RF моделей, обученных только на локальных датасетах.
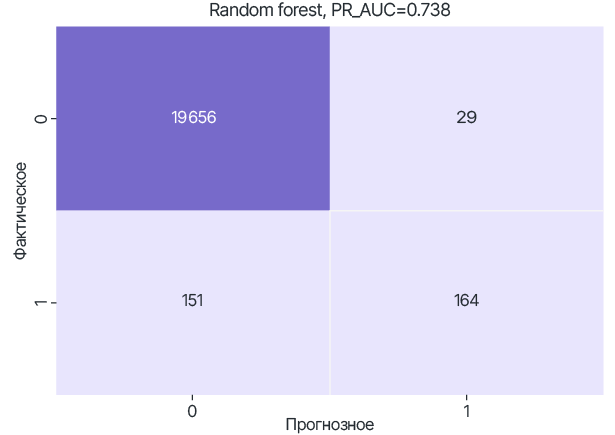
data_A
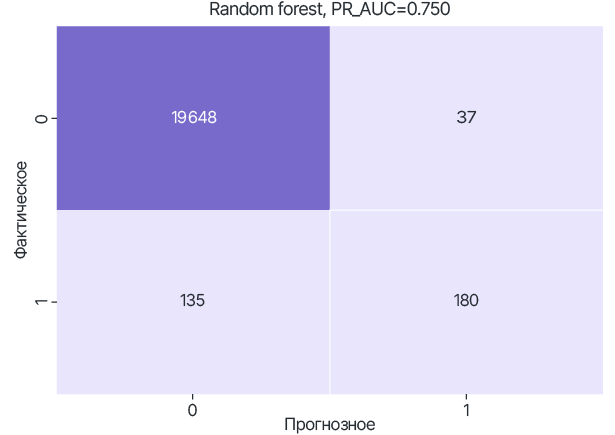
data_B
Guardora разработала федеративное исполнение RF и GBDT моделей.
RF и GBDT модели были федеративно обучены с теми же гиперпараметрами, что и в случаях локального обучения.
Таким образом, согласно метрике PR-AUC лучше себя показала модель RF.
Выходом модели является вероятность принадлежности транзакции к классу мошенничества. Это позволяет выставлять границу принятия решения в зависимости от того, какой тип риска предпочтительнее.

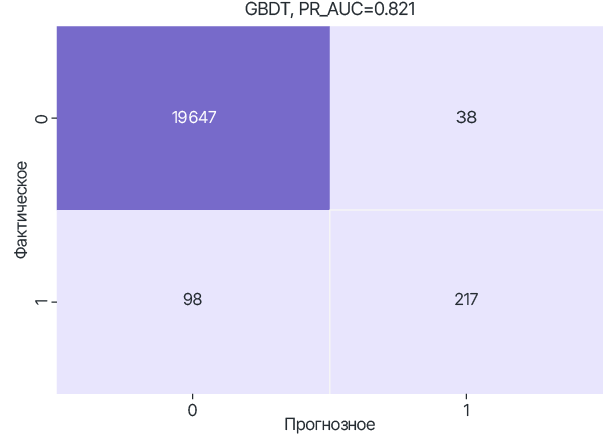
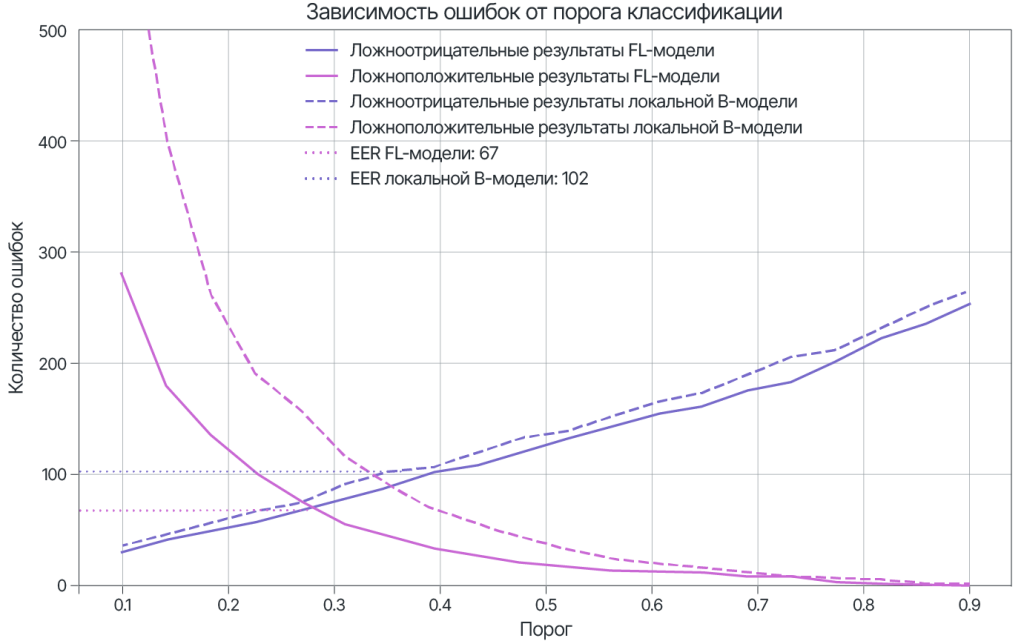
Рисунок демонстрирует соотношение между ложноположительными срабатываниями и ложноотрицательными на тестовом наборе при разных пороговых значениях.
Значения Equal Error Rate (EER), как показателя эффективности модели, также можно видеть на рисунке.
| EER локальной модели | 102 |
| EER FL модели | 67 |
Для модели Random Forest использование FL позволяет улучшить метрику качества PR-AUC до 0.848 (относительно 0.738 для data_A, 0.750 - data_B).
Проанализируем типичные пути решения проблемы нехватки данных конкретного класса на примере data_B как набора с большей долей мошенничества.
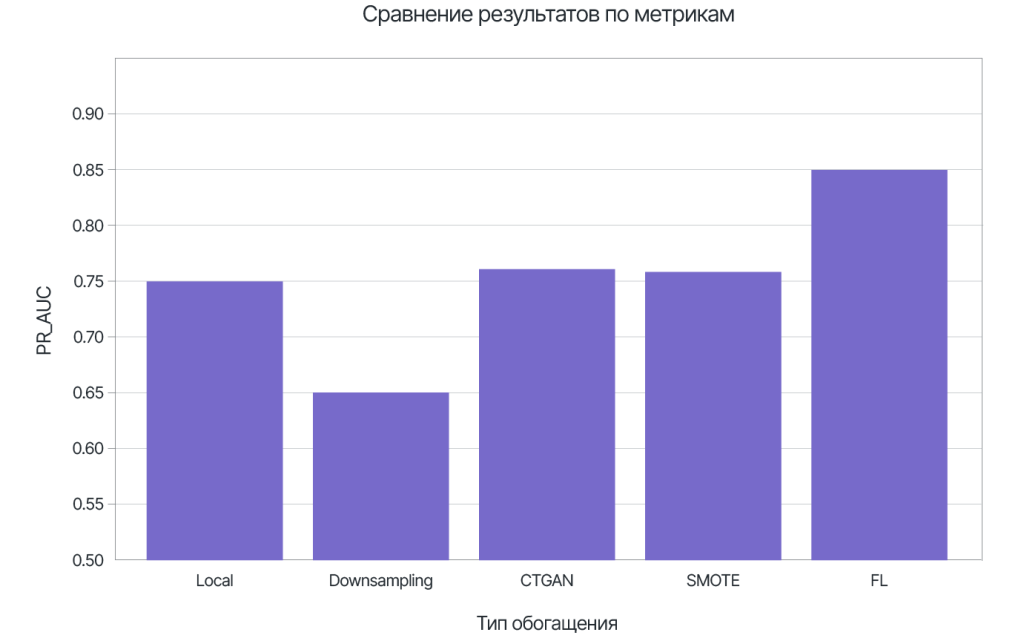
Клиенты небольших организаций тоже заслуживают идентичной защиты от мошенничества.
FL позволяет таким организациям объединяться, использовать данные платежных систем и в результате строить модели, сравнимые по качеству с крупнейшими игроками.
Для платежных систем использование FL позволяет существенно сократить убытки от мошенничества, повысить уровень доверия к самой платежной системе, снизить риски, а также монетизировать знания, извлечённые из своих данных, проводя коллаборативное машинное обучение c малым и средним бизнесом.
Улучшение модели по метрике PR-AUC составило порядка 10 пунктов по сравнению с локальным обучением.
Сокращение ложных срабатываний более чем на 50% при пороге 0.5.
По итогу совместного обучения каждый участник получил идентичный вариант модели, способен проводить независимый инференс и, при необходимости, раунды дообучения с заданной периодичностью, или по мере накопления новых данных.
Сохранение конфиденциальности с одновременным ростом эффективности выявления мошенничества.
Экономия за счет участия во взаимовыгодной безопасной схеме.
Ускорение обновления моделей за счет оперативной реакции на новые типы мошенничеств.

Дополнительные материалы