Давайте сначала представим наиболее распространенный на сегодня кейс машинного обучения. Существует некий субъект, располагающий достаточным количеством данных для обучения какой-либо модели.
Модель может быть произвольной ― от глубоких нейронных сетей до линейной регрессии. Взаимодействие модели с данными рождает решение практической задачи, например, по детектированию объектов, транскрибированию аудио и проч. В действительности данные, с которыми приходится работать модели, исходят не от машины, на которой происходит обучение: они создаются где-то ещё.

Т.е. для проведения анализа данные различных источников должны быть собраны на каком-то центральном сервере ― например, в облаке.
Федеративное обучение (FL от Federated learning) ― парадигма машинного обучения, при которой становится возможным обучение глобальной модели клиентов без совместного использования локальных данных.
Этот подход к машинному обучению не только решает проблемы конфиденциальности данных, но и открывает новые горизонты для разработки безопасных и эффективных моделей.


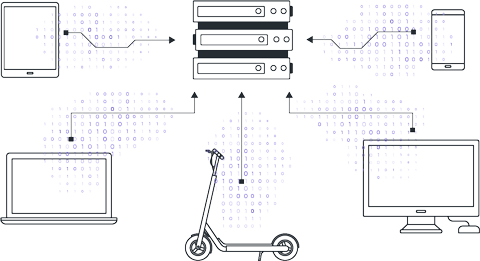
Клиенты согласовывают глобальную модель, функцию потерь, процедуры предобработки данных. Центральный сервер инициализирует глобальную модель случайно или используя предварительно обученный чекпойнт.
Сервер осуществляет рассылку параметров глобальной модели подключённым клиентам. Важно отметить, что каждый клиент начинает обучение, используя одни и те же параметры модели.
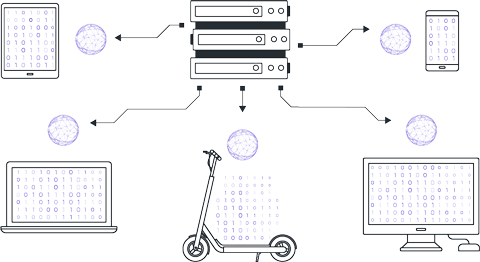
Локальное обучение экземпляров модели клиентами на собственных данных. Локальное обучение выполняется от нескольких степов до нескольких эпох в зависимости от начальных договорённостей.

После шага локального обучения у клиентов формируются модели с различающимися параметрами ввиду различия локальных датасетов. Клиенты возвращают центральному серверу параметры получившихся у них моделей.
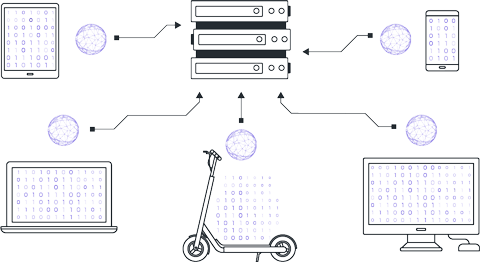
Сервер получает параметры моделей клиентов и осуществляет их агрегирование для обновления параметров глобальной версии.
Существуют различные подходы к процессу агрегирования параметров, но наиболее популярный метод ― FedAvg (Federated Averaging), при котором выполняется взвешенное, в соответствии с объемами локальных датасетов, усреднение полученных параметров.
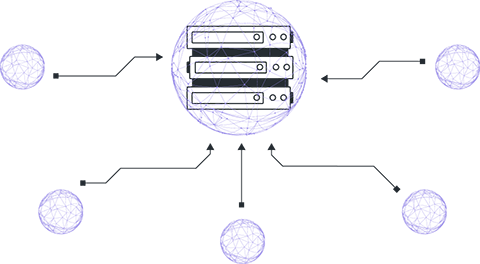
Шаги 1-4 формируют один раунд FL, повторяются до сходимости модели.
Важно отметить, что сами данные остаются на месте, лишь обновления модели передаются на централизованный сервер и другие устройства. Такой подход позволяет сохранять конфиденциальность данных, избегая необходимости централизованной аккумуляции.
Как и любая другая технология, FL, решая поставленную задачу, содержит как положительные, так и отрицательные особенности.
Благодаря тому, что отсутствует передача данных, FL минимизирует риск утечек или несанкционированного доступа к конфиденциальной информации.
Такой подход позволяет эффективно обрабатывать большие объёмы данных и масштабироваться на большое количество устройств без значительного увеличения нагрузки на сеть или вычислительные ресурсы.
Наличие локальных копий моделей, распределение данных среди клиентов позволяет минимизировать уязвимости, связанные с выходом из строя центрального сервера.
FL позволяет значительно распараллелить процесс обучения глобальной модели; нет необходимости оснащения центрального сервера GPU.
Путь данных от источника до модели становится короче; меньше вероятность устаревания или искажения.
Управление процессом обучения со многими клиентами требует сложной системы координации и согласования, что может затруднять развёртывание и поддержку системы.
Различия в наборах клиентских данных могут привести к несогласованности моделей или потере общности в агрегированной модели.
Вычислительные ресурсы на устройствах пользователей могут быть ограничены, что усложняет обучение сложных моделей или требует дополнительной оптимизации алгоритмов.
Возможность атак на отдельные устройства или серверы, хранящие данные или обновления моделей, требует повышенного внимания к защите от киберугроз и мошенничества.
Сложность в поиске владельцев идентичных данных, желающих решить схожую практическую задачу.
Тем не менее FL нашло широкое применение в различных областях, где требуется обработка конфиденциальных данных, таких как медицина (анализ медицинских изображений и данных пациентов), финансовые услуги (анализ транзакций и обнаружение мошенничества) и интернет вещей (обработка данных с датчиков и умных устройств).
Таким образом, FL представляет собой важную технологическую инновацию в сфере PPML (Privacy Preserving Machine Learning), способную изменить ландшафт машинного обучения, сделав его более безопасным и доступным для различных секторов экономики.
Однако для успешного внедрения необходимо учитывать и управлять недостатками и вызовами, которые характерны для данного метода.